Kafka Connect & intégration de données
Intégrer Kafka avec bases de données, systèmes de fichiers, moteurs de recherche et services externes grâce à Kafka Connect, Debezium et les SMT avancées.
Contexte
Kafka Connect est un framework d’intégration distribué permettant de connecter Kafka à des systèmes externes sans écrire de code personnalisé. Il est un composant clé pour les architectures data modernes, en particulier les pipelines CDC (Change Data Capture), l’ingestion massive, l’alimentation de data lakes ou la synchronisation entre services.
Connect peut fonctionner en deux modes :
- Standalone : pour les environnements locaux ou tests.
- Distributed : en production, scalable et tolérant aux pannes.
Il supporte deux types de connecteurs :
- Source : lit une source externe → pousse vers Kafka.
- Sink : lit Kafka → pousse vers un système externe.
Lexique
Importe des données vers Kafka (MySQL, PostgreSQL, MongoDB, etc.).
Envoie les données de Kafka vers un système externe (Elasticsearch, S3, ClickHouse…).
Transformation légère appliquée à chaque message (filtrage, enrichissement, renommage…).
Unités d’exécution parallèle d’un connecteur pour augmenter le débit.
Stocke la position de lecture du connecteur (Kafka interne ou fichier local).
Diagramme
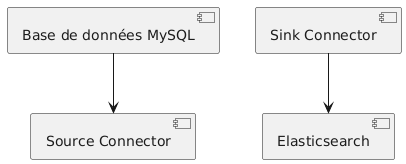
Exemple d’architecture : extraction MySQL (Debezium) → Kafka → S3 Sink + Elasticsearch Sink
Modes de fonctionnement : Standalone vs Distributed
Mode Standalone
- Un seul processus
- Facile pour tests locaux
- Configuration par fichier
- Pas de tolérance aux pannes
Mode Distributed
- Cluster Kafka Connect complet
- Répartition automatique des tâches
- Tolérance aux pannes
- API REST pour gérer les connecteurs
- Scalabilité horizontale
# Lancement mode standalone
connect-standalone.sh connect-standalone.properties mysql-source.properties
# Lancement mode distribué
connect-distributed.sh connect-distributed.properties
Connecteur Source JDBC (lecture depuis MySQL/PostgreSQL)
Le connecteur JDBC permet de lire régulièrement les données depuis une base relationnelle.
{
"name": "mysql-source",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://localhost:3306/ecommerce",
"connection.user": "root",
"connection.password": "secret",
"topic.prefix": "mysql-",
"mode": "incrementing",
"incrementing.column.name": "id",
"poll.interval.ms": "2000"
}
}
Ce mode fonctionne bien pour des tables simples, mais il ne capture pas les mises à jour ni les suppressions.
Debezium & CDC (Change Data Capture)
Debezium détecte les changements en temps réel sur une base (insert/update/delete) et les publie sur Kafka. C’est la méthode moderne d’ingestion.
{
"name": "debezium-postgres",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"plugin.name": "pgoutput",
"database.hostname": "localhost",
"database.port": "5432",
"database.user": "kafka",
"database.password": "password",
"database.dbname": "ecommerce",
"database.server.name": "dbserver1"
}
}
Contenu réservé — connectez-vous.
Sink S3 : alimentation d’un Data Lake
Utilisé pour archiver les données Kafka dans un data lake.
{
"name": "s3-sink",
"config": {
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"topics": "commandes.ecommerce",
"s3.bucket.name": "datalake-ecommerce",
"format.class": "io.confluent.connect.s3.format.avro.AvroFormat",
"flush.size": "500"
}
}
SMT : transformations légères
Les SMT (Single Message Transforms) permettent d’ajuster les messages sans développer un consumer Kafka Streams.
- Renommer une clé
- Masquer une donnée sensible
- Filtrer des événements
- Extraire un champ JSON
"transforms": "mask",
"transforms.mask.type": "org.apache.kafka.connect.transforms.MaskField$Value",
"transforms.mask.fields": "email"
Contenu réservé — connectez-vous.
- Utiliser le mode distribué pour la production.
- Versionner les configurations GitOps (idéal).
- Configurer un Dead Letter Queue (DLQ) pour les erreurs.
- Isoler Kafka Connect dans un réseau sécurisé (ports REST publics = danger).
- Limiter le nombre de tasks pour éviter les surcharges.
Résultat
Les données de MySQL sont automatiquement publiées vers Kafka via JDBC/ Debezium, puis envoyées en temps réel vers Elasticsearch, ClickHouse ou S3 sans écrire de code applicatif.
Résumé
Kafka Connect offre un pipeline d’intégration fiable, scalable et simple à déployer. C’est un composant essentiel pour toute architecture d’événements moderne.
Quiz rapide
- Quelle est la différence entre JDBC Source et Debezium ?
- À quoi sert une SMT ?
- Quel mode utiliser en production ?
- Comment Kafka Connect garantit-il la reprise après incident ?
Exercice pratique
Connectez une base PostgreSQL contenant des commandes à Kafka via Debezium :
- Créer un connecteur Postgres Source
- Vérifier la structure des topics produits
- Configurer un Sink MongoDB
- Observer les events insérés dans MongoDB
Ateliers techniques
Atelier 1 – Pipeline complet MySQL → Kafka → Elasticsearch
- Configurer JDBC Source
- Ajouter SMT de nettoyage
- Envoyer vers un Elasticsearch Sink
- Vérifier l’indexation en temps réel
Atelier 2 – Migration Data Lake S3
- Configurer un Sink S3
- Tester le flush automatique
- Vérifier le format Avro dans le bucket
Atelier 3 – CDC complet : Debezium + enrichissement
- Configurer Debezium Postgres
- Activer les topics
snapshot+update - Ajouter une SMT ExtractField
- Envoyer vers un Sink Snowflake (si disponible)
