Kafka et la durabilité des messages
Comprendre en profondeur les mécanismes de réplication, d’acks, de leadership, d’ISR, de min.insync.replicas et de flush pour garantir une durabilité sans pertes, même en cas de panne sévère.
Contexte
La durabilité est une propriété critique dans les systèmes event-driven. Kafka garantit qu’un message ne disparaît pas, même en cas de :
- panne de broker,
- coupure réseau,
- redémarrage du leader,
- crash du producteur ou du consommateur.
Cette garantie repose sur plusieurs piliers :
- réplication des partitions,
- groupe ISR,
- acknowledgements configurés,
- durabilité disque (fsync, flush),
- politiques de leadership.
Ce chapitre décompose ces mécanismes et fournit une méthodologie pour obtenir une durabilité *réelle* et non théorique.
Lexique
Garantie que les messages ne seront jamais perdus, même après crash.
Confirmation envoyée au producteur quand un message est bien répliqué.
Nombre de copies d’une partition sur différents brokers.
Réplicas à jour, capables de devenir leader sans perte.
Nombre minimal de réplicas synchronisés pour accepter un message.
Politique qui autorise ou interdit un leader non synchronisé (dangereux).
Diagramme
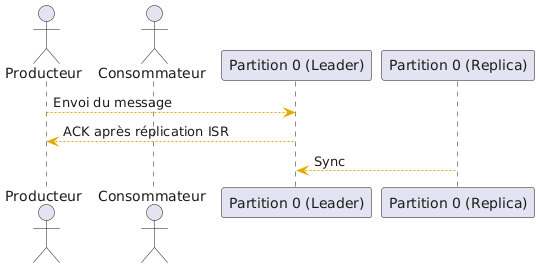
Le leader écrit d’abord localement, puis réplique vers l’ISR. Le message est considéré durable uniquement quand les réplicas en ISR l’ont confirmé.
Commandes pratiques
# Créer un topic durable avec réplication
bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--create \
--topic commandes.ecommerce \
--partitions=2 \
--replication-factor=3
# Vérifier les ISR
bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--describe \
--topic commandes.ecommerce
# Afficher la politique unclean.leader.election
bin/kafka-configs.sh \
--bootstrap-server localhost:9092 \
--entity-type brokers \
--entity-name 1 \
--describe
# Forcer min.insync.replicas
bin/kafka-configs.sh \
--bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name commandes.ecommerce \
--alter --add-config min.insync.replicas=2
Acks, ISR et min.insync.replicas : comprendre leur interaction
acks=0
- le producteur ne reçoit aucune confirmation,
- risque de perte élevé,
- utilisation : jamais en production.
acks=1
- le leader confirme l’écriture locale uniquement,
- perte possible si le leader crash avant réplication,
- utilisation : faible criticité.
acks=all (recommandé)
- le leader attend que tout l’ISR confirme,
- nécessite
min.insync.replicas >= 2, - durabilité optimale.
min.insync.replicas
Le paramètre le plus sous-estimé de Kafka.
- définit combien de réplicas doivent être synchronisés pour accepter un message,
- en dessous : Kafka refuse les writes → « NOT ENOUGH REPLICAS ».
Recommandation Clean Code Craft :
- RF=3, minISR=2, acks=all → configuration la plus sûre.
- Interdiction d’accepter RF=1 en production.
- Interdiction d’utiliser unclean.leader.election=true.
Durabilité disque & interactions avec le système de fichiers
Kafka s’appuie fortement sur le filesystem : chaque message est écrit dans un segment et fsync garantit sa persistance.
Paramètres importants
flush.ms– fréquence de flush disque,flush.messages– nombre de messages avant flush,log.segment.bytes– taille des segments,log.preallocate– pré-allocation pour réduire la fragmentation.
Checklist disque recommandée :
- Disques NVMe recommandés → meilleure latence.
- Filesystem XFS mieux adapté que EXT4 pour Kafka.
- Désactiver barriers si environnement sécurisé.
- Monitorer le temps de fsync.
- Toujours vérifier l’intégrité du ISR.
- Configurer
acks=all+min.insync.replicas>=2. - Activer la réplication sur 3 brokers minimum.
- Monitorer les réplicas hors ISR.
- Ne jamais autoriser unclean.leader.election.
Résultat
Votre cluster Kafka garantit la durabilité réelle des messages même en cas de crash du leader ou de perte d’un broker. Les messages validés sont répliqués, persistés et protégés.
Résumé
La durabilité Kafka repose sur la réplication, le groupe ISR, le mécanisme d’acks, les règles de leadership et les interactions disque. Ces paramètres assurent la fiabilité totale du pipeline de données.
Quiz rapide
- Que signifie ISR ?
- Différence entre acks=1 et acks=all ?
- Quel est l’impact de min.insync.replicas ?
- Quel risque avec unclean.leader.election=true ?
Exercice pratique
Objectifs :
- Créer un topic RF=3.
- Vérifier les ISR.
- Simuler la panne d’un broker.
- Observer le recalcul des ISR.
- Forcer une écriture avec minISR=2.
Ateliers techniques
Atelier 1 — Durabilité stricte : RF=3 + minISR=2 + acks=all
- Créer un topic avec réplication sur 3 brokers.
- Déployer un producteur configuré en acks=all.
- Mesurer le throughput.
- Vérifier le comportement en cas de déconnexion d’un broker.
Atelier 2 — Simulation de perte de messages
- Configurer acks=1 + minISR=1.
- Faire un kill -9 du leader.
- Comparer les offsets avant/après.
- Identifier les conditions exactes de pertes.
Atelier 3 — Optimisation disque avancée
- Changer log.segment.bytes.
- Activer log.preallocate.
- Comparer le temps de flush avant/après.
- Simuler un pic de charge avec kafka-producer-perf-test.
